Accessing PostgreSQL data from AWS Lambda
All databases need some maintenance that we usually perform using scheduled tasks. For example, if you have an RDS instance and you want to get a bloat report once a month, you’ll probably need a small EC2 instance just to do these kinds of things. In this post, we will talk about accessing RDS, getting a result from a SQL statement and reporting it to a slack channel using a scheduled Lambda function; let’s call this poor man’s crontab :)
Before we start, psycopg2 isn’t supported by lambda so it needs to be packaged into the lambda deployment package along with any other dependencies, but since psycopg2 requires libpq it needs to be compiled with libpq statically linked. There are many binaries of psycopg2 that you can download, but I would suggest you compile your own, using the latest PostgreSQL source code. We’ll talk about all these steps throughout this post.
We’ll cover the following:
We’ll cover the following:
- Creating a new AWS postgres RDS instance
- How to compile psycopg (we’ll use docker for that)
- Code for the function
- Packaging
- Lambda function, trigger, schedule
- Testing
I won’t get into much detail about the steps of building an RDS instance as it is pretty straight forward, assuming you have your aws client setup, you’ll need something similar to the following, if not, go to aws console and clickety-click.
#!/bin/sh
aws rds create-db-instance \
--db-subnet-group-name [your subnet group] \
--db-security-groups [your security group] \
--db-instance-identifier [your instance identifier] \
--db-instance-class db.t2.micro \
--engine postgres \
--allocated-storage 5 \
--no-publicly-accessible \
--db-name [your db name] \
--master-username [your username] \
--master-user-password [your password]\
--backup-retention-period 3
The steps for compiling are the following :
# Download sources :
wget -c https://ftp.postgresql.org/pub/source/v11.4/postgresql-11.4.tar.gz
git clone https://github.com/psycopg/psycopg2
# Untar
tar zxfv postgresql-11.4.tar.gz
# Make a local install dir
mkdir ./pgsql-11.4
#configure, compile, install postgres
cd postgresql-11.4 ; ./configure --prefix=/home/postgres/pgsql-11.4 --without-readline --without-zlib
make ; make install
# Edit psycopg2 setup config
cd psycopg2 ;vim setup.cfg
# Change:
static_libpq=1
pg_config=/home/postgres/pgsql-11.4/bin/pg_config
# Compile psycopg2
python3.6 setup.py build
# Package psycopg2
mv ~/psycopg2 ~/psycopg2_source
cp -r ~/psycopg2_source/build/lib.linux-x86_64-3.6/psycopg2/ ~/
tar cvfz psycopg2.tgz psycopg2/
# Finally, get the package from docker, I just used scp
scp psycopg2.tgz vasilis@192.168.1.10:
Next we need to write the Lambda function.
You can find my sample code, along with a binary version of psycopg2 for 11.4, and a deployment script in my repo here.
Keep in mind that the filename (lambda_function.py) and the function name (lambda_handler) are important as they will be defined later when we will create the function in lambda and that the handler has to have this syntax structure :
def handler_name(event, context):
...
return some_value Next, we need to package all these into a “lambda deployment package” AWS documentation can be found here. This is basically a zip that contains all dependencies and the code we want lambda to execute. In my case Slacker (and its dependencies) and the psycopg2 package we compiled earlier. Amazons documentation is pretty clear how to do this, so I won’t repeat the steps here but your zip file should look like this when unzipped:
> tree -L 1
.
├── bin
├── certifi
├── certifi-2019.6.16.dist-info
├── chardet
├── chardet-3.0.4.dist-info
├── config.py
├── idna
├── idna-2.8.dist-info
├── lambda_function.py
├── psycopg2
├── requests
├── requests-2.22.0.dist-info
├── slacker
├── slacker-0.13.0.dist-info
├── urllib3
├── urllib3-1.25.3.dist-info
└── util.py

Next screen, on the left side where triggers are, pick cloudwatch events, we’ll use these events to schedule how often the function will run, we also should put python 3.6 in runtime and in Handler we make sure that it matches the filename.hundler_function_name of our code.
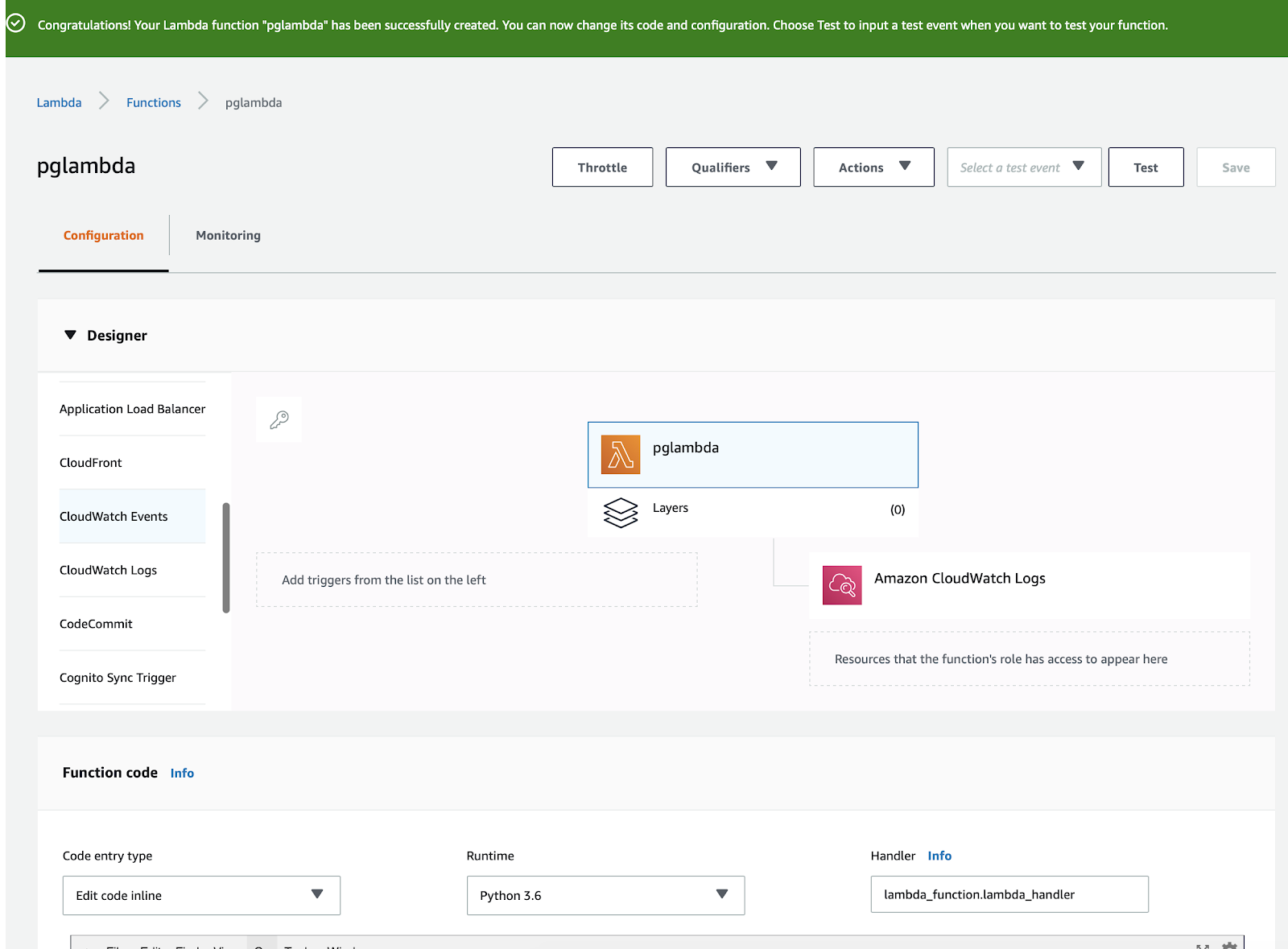
Next screen you’ll have to create a new rule and write a schedule expression :
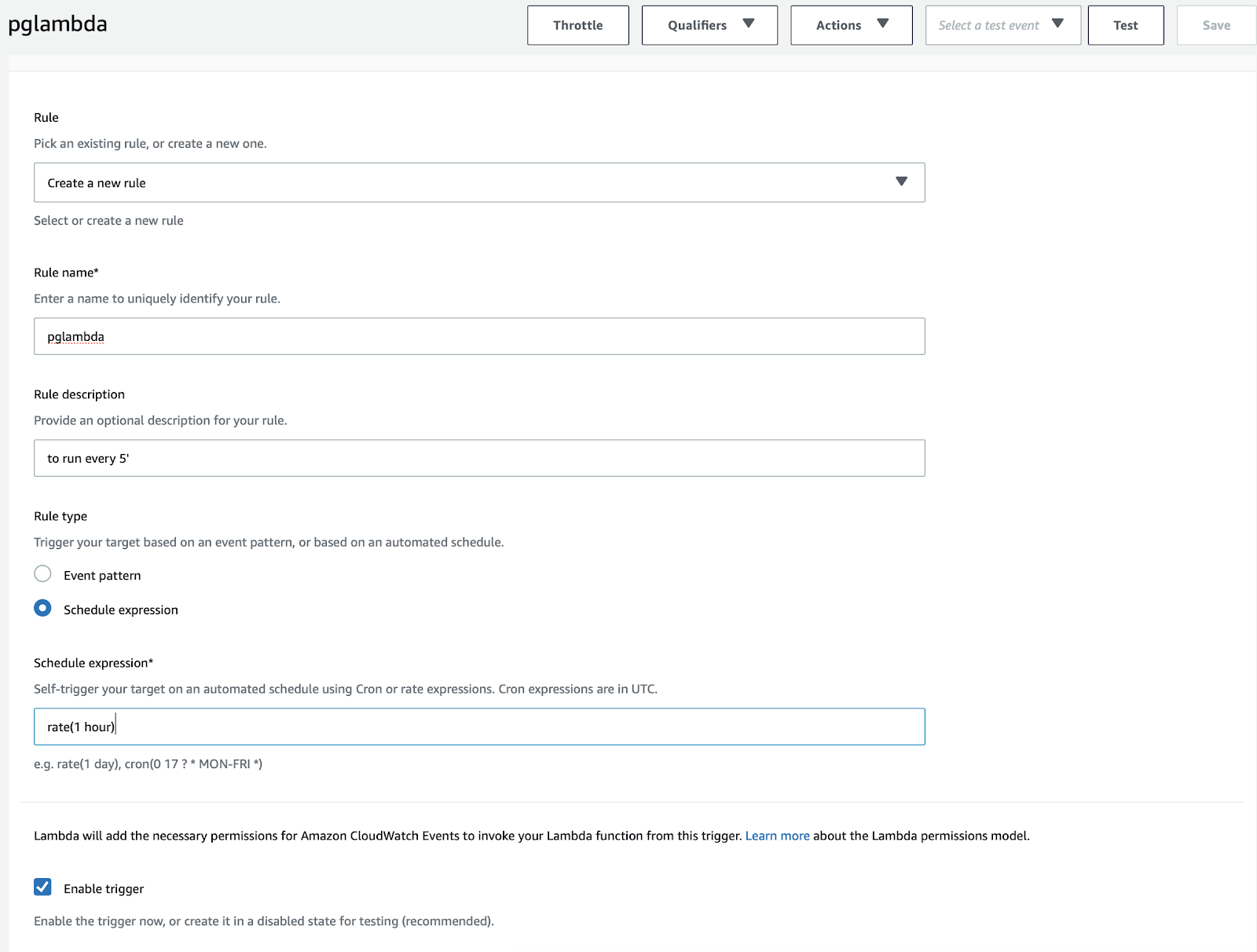
This schedule expression accepts ‘rate’ or a cron expression, see AWS documentation here.
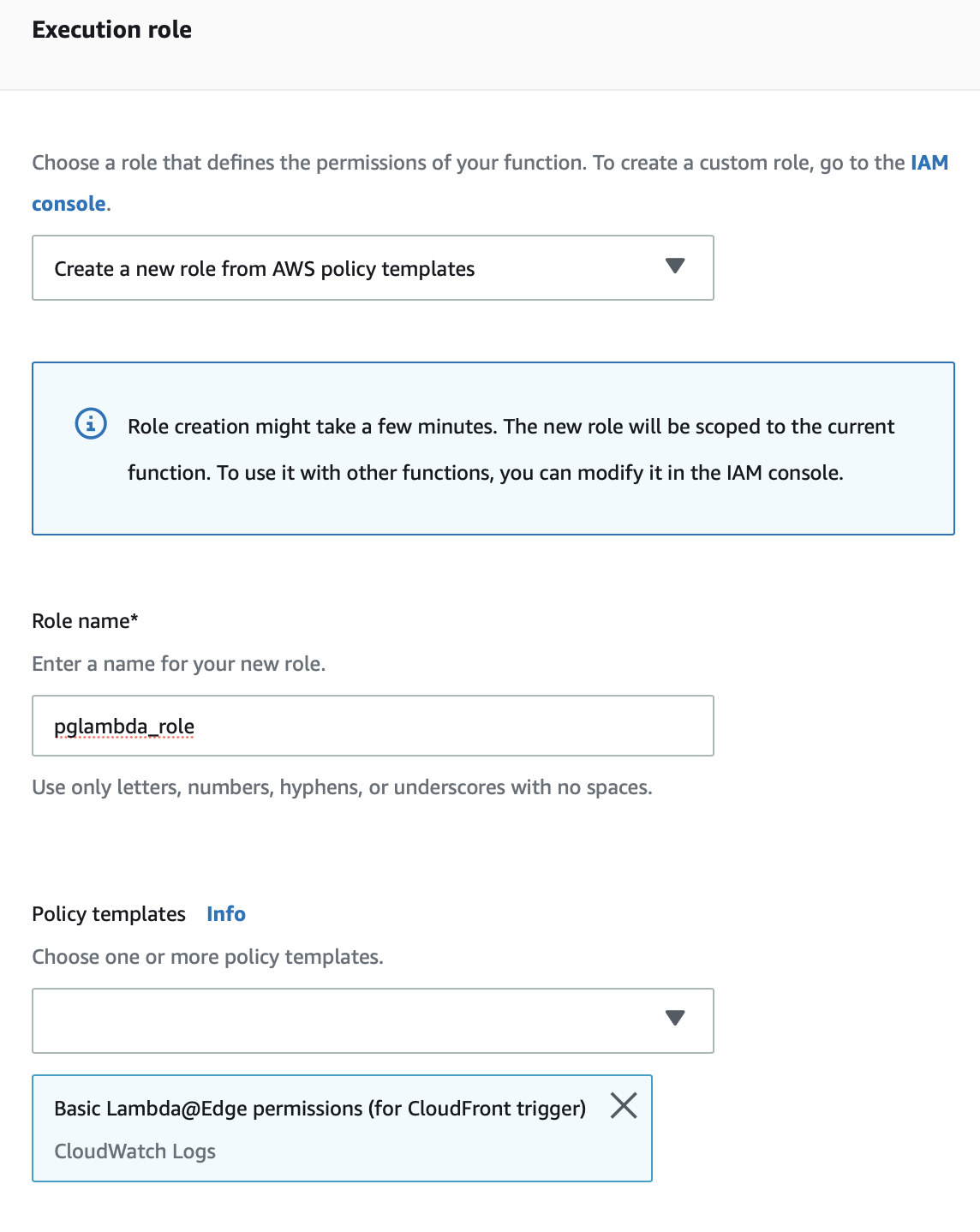
From the function main page in aws console, scroll down to network, add your VPC and last, At ‘Execution role’ add a role or create a new one like the following :
As you may have noticed, I haven't added any code yet. You can add your zip from the console :

I found it much easier to use a script like the following in order to make testing a bit less tedious. Keep in mind that the following script requires AWS CLI installed:
Lambda is cool.. kinda, and having a way to schedule simple postgres tasks without having a server, or an ec2 instance is nice, but this is by no means a replacement for crontab, simply because lambda has a lot of limitations. Say you wanted a pgbadger report sent everyday, you are out of luck. Perl is not supported in lambda. But if you want a bloat report or any SQL statement executed on a schedule, lambda could be a solution.
As mentioned before, dockerfile , scripts and a binary of psycopg2 (against pg11.4) can be found here.
Thanks for reading
Vasilis Ventirozos
https://www.credativ.com
Next screen you’ll have to create a new rule and write a schedule expression :
This schedule expression accepts ‘rate’ or a cron expression, see AWS documentation here.
From the function main page in aws console, scroll down to network, add your VPC and last, At ‘Execution role’ add a role or create a new one like the following :
As you may have noticed, I haven't added any code yet. You can add your zip from the console :
I found it much easier to use a script like the following in order to make testing a bit less tedious. Keep in mind that the following script requires AWS CLI installed:
home=/Users/vasilis/Work/working_on/projects/lambda/packaging
cp ./function_work_in_progress.py ./lambda_function.py
rm -f package.zip
cd packages ; zip -r9 /Users/vasilis/Work/working_on/projects/lambda/packaging/function.zip .
cd $home
zip -g function.zip lambda_function.py
zip -g function.zip config.py
zip -g function.zip util.py
aws lambda update-function-code --function-name pg_lambda --zip-file fileb://function.zip
sleep 2
rm -f outfile ;aws lambda invoke --function-name "pg_lambda" outfile ;cat outfileLambda is cool.. kinda, and having a way to schedule simple postgres tasks without having a server, or an ec2 instance is nice, but this is by no means a replacement for crontab, simply because lambda has a lot of limitations. Say you wanted a pgbadger report sent everyday, you are out of luck. Perl is not supported in lambda. But if you want a bloat report or any SQL statement executed on a schedule, lambda could be a solution.
As mentioned before, dockerfile , scripts and a binary of psycopg2 (against pg11.4) can be found here.
Thanks for reading
Vasilis Ventirozos
https://www.credativ.com

This comment has been removed by a blog administrator.
ReplyDeleteGood Information
ReplyDeleteYaaron Studios is one of the rapidly growing editing studios in Hyderabad. We are the best Video Editing services in Hyderabad. We provides best graphic works like logo reveals, corporate presentation Etc. And also we gives the best Outdoor/Indoor shoots and Ad Making services.
Best video editing services in Hyderabad,ameerpet
Best Graphic Designing services in Hyderabad,ameerpet
Best Ad Making services in Hyderabad,ameerpet
I think this is one of the most important info for me.And i am glad reading your article. But want to remark on few general things, The site style is good , the articles is really excellent and also check Our Profile for devops training and devops videos.
ReplyDelete
ReplyDeleteThanks for provide great informatic and looking beautiful blog, really nice required information & the things i never imagined and i would request, wright more blog and blog post like that for us. Thanks you once agian
birth certificate in delhi
name add in birth certificate
birth certificate in gurgaon
birth certificate correction
birth certificate in noida
birth certificate online
birth certificate in ghaziabad
birth certificate in india
birth certificate apply online
birth certificate in bengaluru
ReplyDeleteIt was so good to read and usefull to improve knowledge. Keep posting. If you are looking for any python related information please visit our website DevOps Training in Bangalore | Certification | Online Training Course institute | DevOps Training in Hyderabad | Certification | Online Training Course institute | DevOps Training in Coimbatore | Certification | Online Training Course institute | DevOps Online Training | Certification | Devops Training Online
This article will help the internet people for building up new webpage or even a weblog from start to end.
ReplyDeletesql server developer online training
informatica online training
malatya eskort
ReplyDeleteağrı eskort
adana eskort
edirne eskort
zonguldak eskort
rize eskort
balıkesir eskort
karabük eskort
kırşehir eskort
konak eskort
adapazarı eskort
ReplyDeleteadana eskort
aksaray eskort
bartın eskort
yalova eskort
eskort
düzce masöz
manisa masöz
Mmorpg oyunları
ReplyDeleteInstagram takipçi satın al
TİKTOK JETON HİLESİ
TİKTOK JETON HİLESİ
saç ekimi antalya
TAKİPÇİ SATIN AL
İnstagram takipçi satın al
Mt2 Pvp
instagram takipçi satın al
smm panel
ReplyDeleteSMM PANEL
İs İlanlari Blog
instagram takipçi satın al
hirdavatciburada.com
beyazesyateknikservisi.com.tr
SERVİS
tiktok jeton hilesi
great
ReplyDeleteExcellent post explaining how to access PostgreSQL data from AWS Lambda efficiently. Serverless integration with databases can be challenging without proper configuration and monitoring. Businesses looking for dependable postgresql support services should definitely consider GeoPITS for expert database management and support.
ReplyDelete